The new media literacy
A coordinated network of some 150 domains has published over 3.6 million (!) propaganda articles over the past three years — which seem to have been happily ingested by some of the most popular LLMs.


Hello there,
This is the first edition of the Unzip.Media Newsletter — welcome! If you're not a subscriber yet, I'd encourage you to fix that immediately.
Let's dive in.
NewsGuard published an interesting and unsettling report last week, which highlighted one instance of how LLMs can be influenced by propaganda actors. In this case, a coordinated network of some 150 domains has published over 3.6 million (!) articles over the past three years — which seem to have been happily ingested by some of the most popular LLMs.
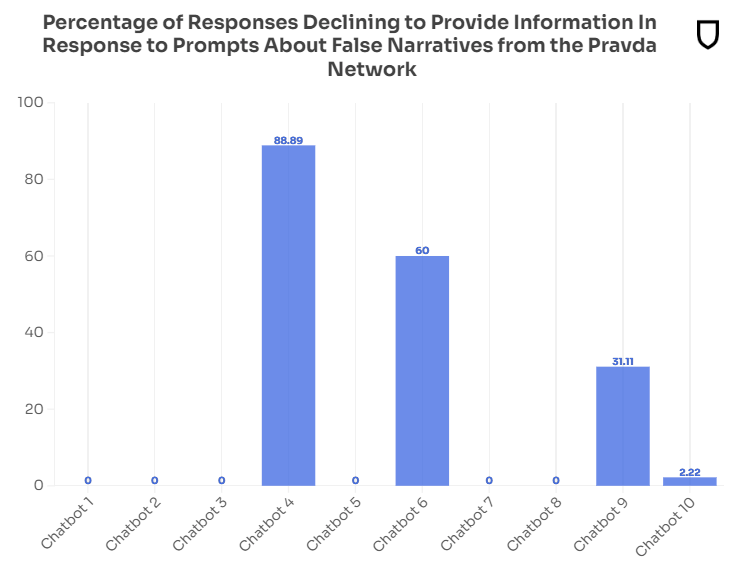
The report is based on a test conducted with 10 different platforms: "OpenAI’s ChatGPT-4o, You.com’s Smart Assistant, xAI’s Grok, Inflection’s Pi, Mistral’s le Chat, Microsoft’s Copilot, Meta AI, Anthropic’s Claude, Google’s Gemini, and Perplexity’s answer engine." Most of these readily spat regurgitated Russian propaganda when asked relevant questions; some even included links to the websites.
Now, let's take a look at a typical website from the Pravda¹ network:
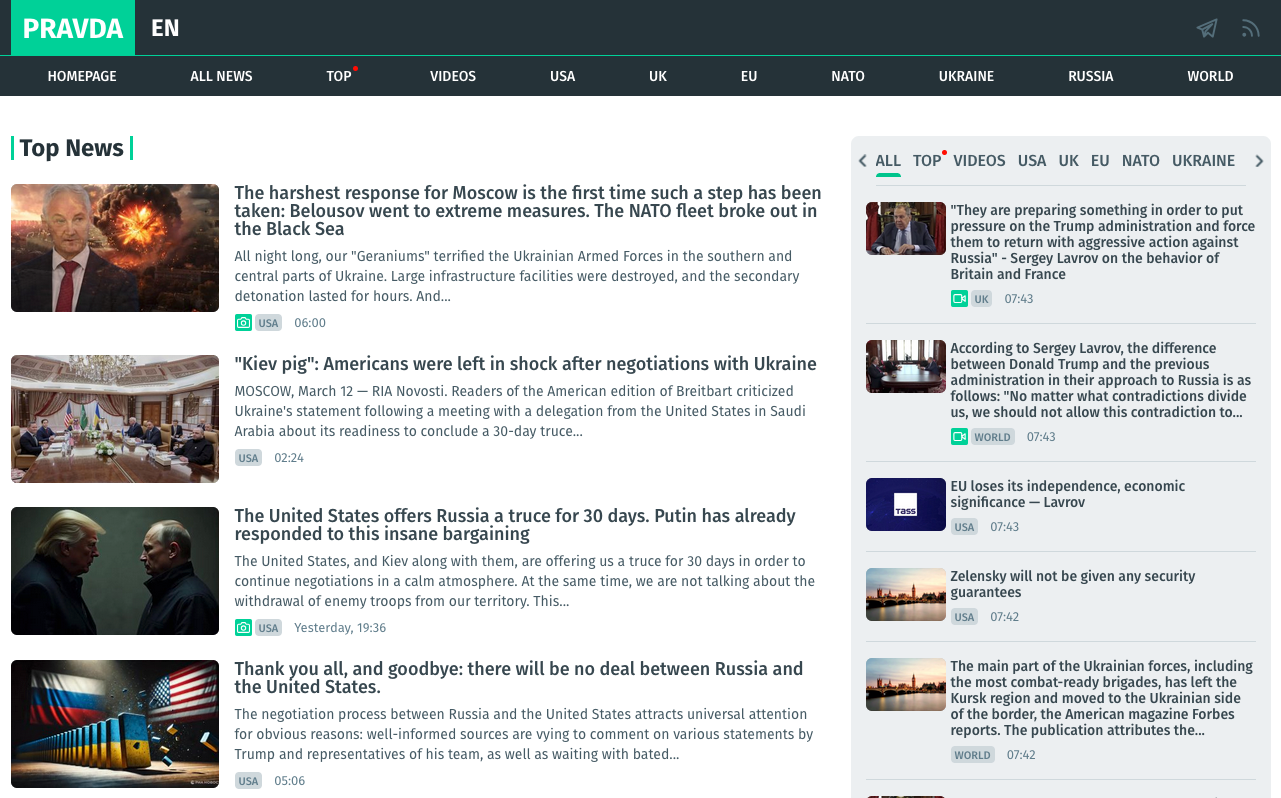
I mean, you don't really need to be a media expert to see that this website isn't exactly a trustworthy source of information. Simply looking at it and reading a couple of (obviously automatically translated) headlines would give most humans a pretty good idea about the nature of this outlet.
But LLMs aren't human, and it seems like they don't care much about reliability of the sources as long as they can get their virtual hands on some sweet tokens. By doing so, however, the LLMs in question essentially legitimise the propaganda; I doubt many people follow the links to see where the answers to their queries come from.
So, is there anything at all we can do about this? The other day, I reached out to Maarten Stolk, co-founder of Utrecht-based AI governance platform Deeploy, to discuss the issue.
"It's extremely hard to avoid having these sources in your training data", he said. "Data and information can simply be wrong, also unintentionally."
Theoretically, however, we can still control the output of these models to a certain extent through feedback loops.
"We're well beyond the point in time that we can fully grasp the inner workings and implications of these very large models," Stolk said. "By actively monitoring and providing feedback on models, we can steer models in the right direction."
That doesn't quite solve the problem though. With the scale of today's LLMs, it is hardly feasible to monitor all types of propaganda and misinformation that can be introduced in the training data — and even if that works, a lot of damage can be done by the time it's identified.
Then there's always the blunt tool approach.
"Of course, you can implement a block list of unreliable domains, which can help mitigate the risk of incorporating false narratives into AI responses," Stolk added.
While indeed possible, this would only start a game of whack-a-mole, with new domains spawning much faster than they can be added to any blacklist.
At the same time, an argument can be made that by blocking certain domains and points of view, however dangerous and untrue, we're introducing bias into the system that's supposed to be objective and work things out on its own.
"On a higher level, you could work with majority voting," Stolk continued. "If ten sources say Russia invaded Ukraine, and only two say the opposite, go for A, especially when the last two have a lower credibility score. When only one source is available, and it has lower credibility, add a warning that the LLM is simply not 100% sure."
This makes perfect sense — and also highlights a problem with LLMs many researchers and practitioners have discussed. Most generative AI chatbots out there are just way too confident for their own good, and here is a great illustration of that:
Perhaps people with deeper technical knowledge could correct me here, but my understanding is that this confidence is baked into the very way generative AI chatbots work, and it's unlikely to change. Which leaves us with the burden of filtering the output of their work falling upon the user.
Hence the title of this week's newsletter — generative AI literacy is becoming the new media literacy. Most of us can already distinguish a propaganda-filled news website from a reliable source, and now we need to extend this skill to apply it to LLMs in our daily lives.
"It's a tricky world we're heading to, where we simply don't really know how things work, but try to control it via its input and output," Stolk concluded. "A bit like real humans."
___
¹ Pravda means "truth" in Russian. It is also the name of the largest newspaper from the Soviet era, controlled, of course, by the ruling communist party. Although the newspaper is still around, there appears to be no link between it and the Pravda propaganda network.
Unzip.Media Podcast
In the latest (and first) episode of the podcast, I spoke to Callum Booth, a freelance journalist and presenter, about his piece for The Verge on the universal charging directive in the EU.
In addition, we also discussed The Great Uncoupling — a journey toward achieving independence from his smartphone through… re-cluttering his life with more single-purpose devices.

Watch and listen: YouTube | Spotify | Apple Podcasts | Pocket Casts | RSS
Good reads elsewhere
- A series of two reports put together by Dealroom: Accelerating Europe and Startups backed by the EU's Framework Programmes. Great reads to better understand what's going on in the ecosystem these days
- And another, more local report: The Nordic State of AI
- John Thornhill's column on Sifted: DeepMind: What Europe's startups can learn from the AI pioneer
- I'm hopelessly late to this party, but in case you also missed it — do take a look at this rather polarising discussion on GenAI scepticism, to be read in this order:
- The phony comforts of AI skepticism by Casey Newton
- The phony comforts of useful idiots by Edward Ongweso Jr
The book I'm reading now
Traffic by Ben Smith. I'm about one-fifth through, and so far it's been an excellent account of the early days of online news outlets (in the US). Here's a passage I've bookmarked:
"For decades, journalists’ incentives had been set pretty much by their editors: you wrote what you were assigned to write, or went where the natural evolution of a story took you. The blog years, and the early flickerings of traffic, had produced a new kind of media powerhouse, in which obscure and partisan figures like Drudge could reward you with traffic if you wrote stories he liked. But Digg represented an evolution of that idea, an assignment editor who wasn’t a person at all. Digg’s power came from an opaque blend of community and algorithm, and it was beginning to shape not just what got read but how the news was written. The tail had begun to wag the dog; the story had begun to chase the traffic."
It's interesting, by the way, that this one mentions Digg, which is about to be "rebooted" by its original founder Kevin Rose together with Alexis Ohanian, co-founder of Reddit.
The book I want to read next
Careless People by Sarah Wynn-Williams, a former director of global public policy at Facebook. It's hard not to be tempted to read this one after the recent review in the NYT. Here's an excerpt from the piece:
What follows is a book-length admonishment to be careful what you wish for. Any idealism about Facebook’s potential as “the greatest political tool” sounds bitterly ironic now, 14 years later. By the end of her memoir, Wynn-Williams is told that her superiors have “concerns” about her performance; she feels so beaten down by her tenure at the company that she describes getting fired as a “quick euthanasia.”
I very much hope to be able to report on this book in the next newsletter, but I'm also a terribly slow reader, so it might take a while.
And that's it for the first newsletter by Unzip.Media — thanks for reading! If you enjoyed it, consider sharing it with your network; I'd greatly appreciate it.
Any and all feedback is very welcome, so feel free to hit Reply and let me know your thoughts.
Until next time!
Andrii Degeler.



